Discourse Features and Constituents
27 May 2017
Discourse Features and Treebank Constituents
- Reframing a Question
When I first looked at the data of Levinsohn’s Greek New Testament Discourse Features - which is similar to Steven Runge’s Lexham Discourse Greek New Testament Datasets - I noticed that these features are defined for words or spans, these spans provide explicit support for split constituents, and they generally seem to align with the boundaries of constituents in the Lowfat Treebanks. In other words, it looked like Levinsohn’s Discourse Features was based on constituents that generally seem to be the same constituents as our Lowfat Trees. So I asked about this on B-Greek in a thread called Discourse Features and Treebanks. Mike Aubrey and Stephen Carlson both seemed to think I was asking the wrong kind of question - since they are two fiercely intelligent people whom I respect deeply, with much more background in linguistics than I have and a track record for getting things right, I want to learn from them. At the same time, I am not sure I agree with everything they are saying. Perhaps reframing the question will help.
Asking a Better Question
I’m not sure I asked the right question. During this discussion and a variety of side discussions, I think I have learned how to ask a better question. Micheal Palmer, James Tauber, and Christopher Land have been particularly helpful in reframing my question. Here are some premises, followed by the question.
- Syntax trees describe the information found in individual sentences.
- Discourse Analysis and Information Flow discuss the meaning of larger units like passages.
- Discourse Grammar brings discourse features down to the level of individual sentences.
- The discourse features found in discourse grammars are based on spans that look like the same constituents found in syntax trees.
- Wallace Chafe’s Information Flow also seems to acknowledge constituents that have a hierarchical relationship.
- The differences among various linguistic theories of syntax are not about the constituents and hierarchical relationships found in syntax trees, they are about more complex issues involving the relationship between syntax and meaning, human cognition, language acquisition, etc. Even those theories that use a flat structure for their analysis acknowledge the relationships among constituents, using a different model than treebanks, but a model that still accounts for constituents and hierachical relationships.
As an example of that last point, here is Wallace Chafe’s analysis of the sentence my father laughed.
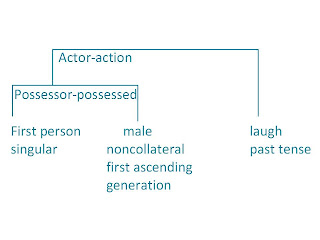
Now for the question, which is actually a set of questions:
- Are the constituents used in syntax trees the same constituents used for Discourse Grammar?
- Are these, in turn, the basic constituents used for Discourse Analysis and Information Flow?
- If they differ, does that mean that one of these analyses needs to be improved, or do they have different criteria for identifying a constituent that lead to different conclusions?
- If the criteria for identifying a constituent differ, how, and why?
The answers to these questions are useful for the data modeling we are doing when we construct treebanks. In my original question, I asked about the relationship between the propositional hierarchies found in Levinsohn’s analysis and the hierarchies found in syntax trees. I now think I understand the answer to that question. Here’s an analogy: books merge sentences into paragraphs, sections, and chapters, and it would be harder to read a book that focused on the structure of each individual sentence. In the same way, any analysis that looks at paragraphs, pericopes, or other larger units needs to model the flow of information across these units, in which the boundaries between sentences is not important, and the focus is on the bigger picture. Once you get beyond the individual sentence, trees are not particularly useful, and are more trouble than they are worth. Models of these larger units are not built by concatenating syntax trees or creating one massive tree that has intact syntax trees at lower levels. Still, it seems reasonable to suspect that models beyond the sentence level rely on constituents found in sentences, and that constituents at various levels may have similar constituency tests.
History of Syntactic Theory: A Useful Detour
Partly in response to this, Mike Aubrey started an overview of the history of syntactic theory, starting with these posts:
- A brief history of syntactic theory: Early Chomsky
- A brief history of syntactic theory: Parallel-constraint based syntax
These are good articles, and I look forward to the rest of the series, but so far I am not sure that they answer my original question, perhaps because I did not phrase it clearly. So far, my window on this history comes largely from reading parts of Stefan Mueller’s Grammatical theory: From transformational grammar to constraint-based approaches and Peter Culicover and Ray Jackendoff’s Simpler Syntax, a book Mike Aubrey recommended to me a while ago. Mike knows more about this history than I do, but here is my understanding based on my current knowledge: Syntax trees represent the constituents of a sentence and the relationships among constituents. This is equally true for dependency syntax trees and constituency syntax trees, as well as those that take a hybrid approach - they all have constituents and hierarchical relationships. People generally do not communicate via individual sentences, they have conversations or read passages, articles, or books. Linguists are often interested in the meaning of a passage, how humans produce and understand language, how language is acquired, the rules that govern sentence structure, and many other questions that operate beyond the level of syntax trees. Syntax trees are useful data for exploring these questions, but the purpose of syntax trees is to provide a systematic model of the data found in sentences. This can be done without answering the questions that linguists debate about what happens at higher levels, because linguists generally agree about the kinds of things that syntax trees represent, even if they use different vocabularly and different models. In particular, they agree that a good model of syntax should have a notion like constituents, groups of words that function as a single unit within a hierarchical structure.
Linguists who study syntax are divided largely into two camps. Simpler Syntax calls one of these camps Mainstream Generative Grammar (MGG), which includes various theories associated with Noam Chomsky that have some notion of “deep structure”, seen as the basic propositional meaning of the sentence, and a set of transformations that create the surface structure of a sentence adapted to the real world context. Simpler Syntax talks about a group of alternative theories of generative syntax that disagree with Chomsky and largely agree with each other, including Head-Driven Phrase Structure Grammar (HPSG), Lexical-Functional Grammar (LFG), Construction Grammar, and other theories that share a significant commonality with these, including Role and Reference Grammar. Except for Role and Reference Grammar, all of these have constituents with hierarchical relationships.
I don’t know much about Role and Reference Grammar, which uses grammatical functions instead of trees. In general, functions are closely related to trees. It’s quite possible that these grammatical functions are equivalent to a tree-based representation or graph-based representation that has constituents and relationships similar to those found in other models. It’s quite possible that syntax trees could be converted to a Role and Reference Grammar - this is something I hope to explore with Mike in the future. These are questions beyond my ability to answer without a lot of reading and a lot of work. Mike suggests that Role and Reference Grammar may be particularly helpful at spanning the gap between individual sentences and larger discourse units. I hope to learn more.
Separation of Concerns and Syntax Trees
Syntax trees do one thing: they provide a systematic, consistent account of the basic structure of each sentence in the corpus, modeling constituents and their relationships. It is not easy to do this well, and it takes time to understand and model each sentence, but syntax trees are much simpler than the concerns that divide the various schools of syntax, and much simpler than accounting for information flow across larger units than the sentence.
Thinking about what Mike wrote on B-Greek and on his blog together with a long discussion we had on this topic, I suspect we might be able to simplify discussion significantly by focusing on these things:
- The best model for separation of concerns among syntax trees and other linguistic models.
- Circumscribing syntax trees by being very clear about what is in a syntax tree and what is not. Circumscription stipulates that a given model is about the things found in the model, and nothing else.
- Examining the constituent criteria of syntax trees, discourse grammar, discourse analysis, information flow, etc. to see if the same constituents can be used at multiple levels of analysis.
One concrete example of circumscription. In my initial question, I asked whether it would be useful for syntax trees to identify topic and focus or P1 and P2, constructs from Discourse Grammar. I think the answer is simply that we should separate concerns and avoid conflating levels of analysis. A software application might use both syntax trees and discourse features to create a meaningful display, but they should not be conflated in the base datasets. In the syntax trees per se, it is quite easy to determine whether there are constituents before the verb, and clauses are available for other levels of analysis that might look at topic and focus or other issues. But it is useful to ensure that these constituents are as useful as possible for other analyses, if only because this is a significant task and time and research money are scarce.
I also asked whether I should be bothered that Levinsohn depicts these constituents with a quite different hierarchy. I don’t think this should bother me. Different levels of analysis can choose whatever is useful from lower levels, and there will always be more than one useful hierarchy for analyizing a set of sentences that combine into larger units. And some approaches to analysis do not rely on hierarchy at all.